Глава 19: Оценка и мониторинг
Данная глава рассматривает методологии, которые позволяют интеллектуальным агентам систематически оценивать свою производительность, отслеживать прогресс в достижении целей и выявлять операционные аномалии. В то время как глава 11 описывает постановку целей и мониторинг, а глава 17 рассматривает механизмы рассуждения, данная глава фокусируется на непрерывном, часто внешнем, измерении эффективности агента, его производительности и соответствия требованиям. Это включает определение метрик, установление циклов обратной связи и внедрение систем отчетности для обеспечения того, чтобы производительность агента соответствовала ожиданиям в операционных средах (см. рис. 1).
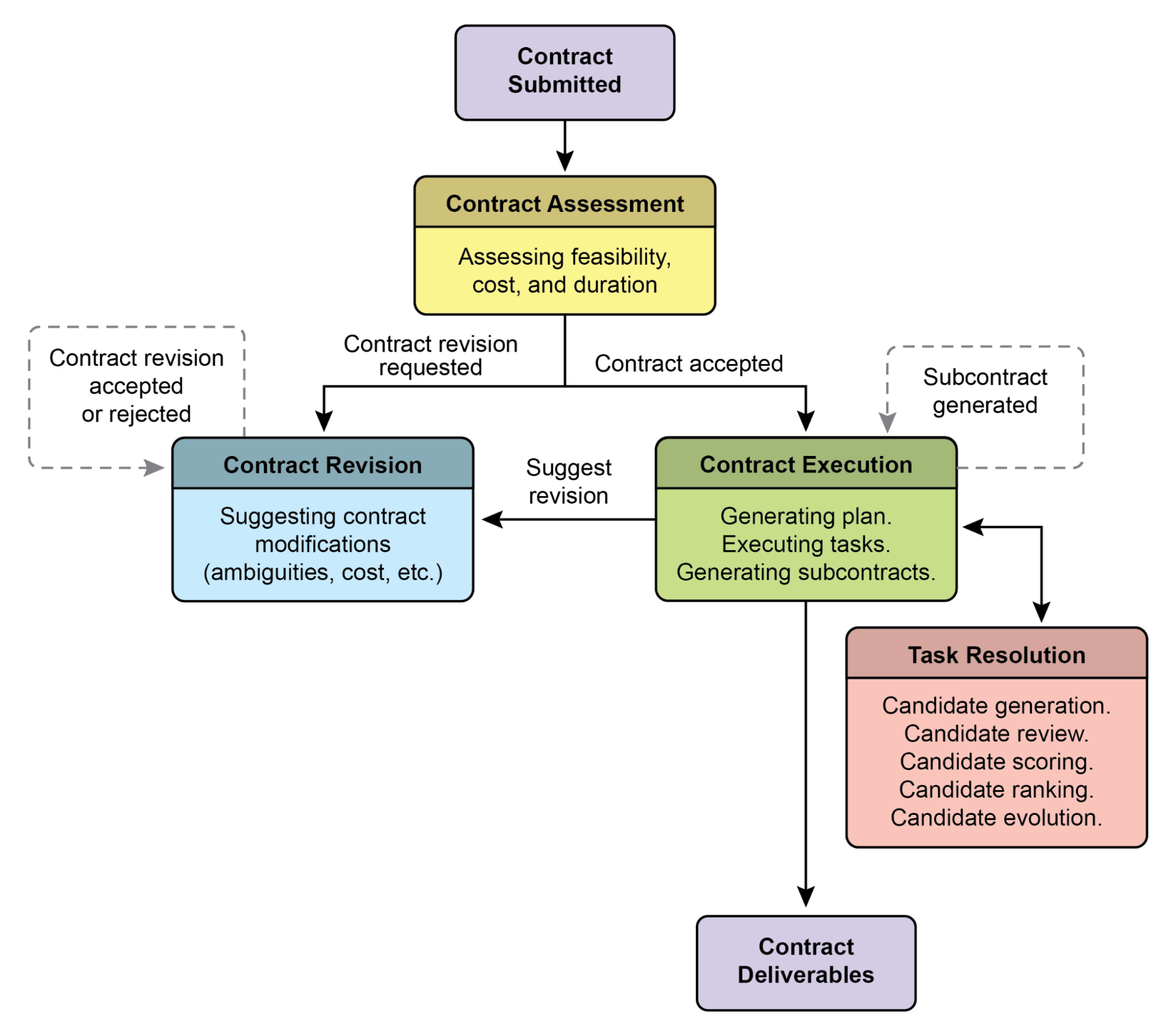
Рис. 1. Лучшие практики для оценки и мониторинга
Практические применения и случаи использования
Наиболее распространенные применения и случаи использования:
Отслеживание производительности в живых системах: Непрерывный мониторинг точности, латентности и потребления ресурсов агента, развернутого в производственной среде (например, показатель разрешения проблем чат-бота службы поддержки клиентов, время отклика).
A/B тестирование для улучшения агентов: Систематическое сравнение производительности различных версий агентов или стратегий параллельно для выявления оптимальных подходов (например, тестирование двух различных алгоритмов планирования для логистического агента).
Аудиты соответствия и безопасности: Генерация автоматических отчетов аудита, которые отслеживают соответствие агента этическим руководящим принципам, регуляторным требованиям и протоколам безопасности с течением времени. Эти отчеты могут быть проверены человеком в контуре или другим агентом, и могут генерировать KPI или запускать предупреждения при выявлении проблем.
Корпоративные системы: Для управления Agentic AI в корпоративных системах необходим новый инструмент контроля - AI "Контракт". Это динамическое соглашение кодифицирует цели, правила и средства контроля для задач, делегированных AI.
Обнаружение дрейфа: Мониторинг релевантности или точности выходных данных агента с течением времени, обнаружение случаев, когда его производительность ухудшается из-за изменений в распределении входных данных (концептуальный дрейф) или изменений в окружающей среде.
Обнаружение аномалий в поведении агента: Выявление необычных или неожиданных действий, предпринимаемых агентом, которые могут указывать на ошибку, вредоносную атаку или нежелательное эмерджентное поведение.
Оценка прогресса обучения: Для агентов, предназначенных для обучения, отслеживание их кривой обучения, улучшения конкретных навыков или способностей к обобщению на различных задачах или наборах данных.
Практический пример кода
Разработка комплексной системы оценки для AI агентов представляет собой сложную задачу, сопоставимую по сложности с академической дисциплиной или значительной публикацией. Эта сложность проистекает из множества факторов, которые необходимо учитывать, таких как производительность модели, взаимодействие с пользователем, этические последствия и более широкое общественное воздействие. Тем не менее, для практической реализации фокус может быть сужен до критических случаев использования, необходимых для эффективного и результативного функционирования AI агентов.
Оценка ответов агента: Этот основной процесс необходим для оценки качества и точности выходных данных агента. Он включает определение того, предоставляет ли агент релевантную, корректную, логичную, беспристрастную и точную информацию в ответ на заданные входные данные. Метрики оценки могут включать фактическую корректность, беглость, грамматическую точность и соответствие предполагаемой цели пользователя.
def evaluate_response_accuracy(agent_output: str, expected_output: str) -> float:
"""Вычисляет простую оценку точности для ответов агента."""
# Это очень базовое точное совпадение; в реальном мире использовались бы более сложные метрики
return 1.0 if agent_output.strip().lower() == expected_output.strip().lower() else 0.0
# Пример использования
agent_response = "Столица Франции - Париж."
ground_truth = "Париж является столицей Франции."
score = evaluate_response_accuracy(agent_response, ground_truth)
print(f"Точность ответа: {score}")Python функция evaluate_response_accuracy вычисляет базовую оценку точности для ответа AI агента, выполняя точное сравнение без учета регистра между выходными данными агента и ожидаемыми выходными данными после удаления ведущих или завершающих пробелов. Она возвращает оценку 1.0 для точного совпадения и 0.0 в противном случае, представляя бинарную оценку правильно/неправильно. Этот метод, хотя и прямолинеен для простых проверок, не учитывает вариации, такие как перефразирование или семантическая эквивалентность.
Проблема заключается в методе сравнения. Функция выполняет строгое, символ-за-символом сравнение двух строк. В приведенном примере:
- agent_response: "Столица Франции - Париж."
- ground_truth: "Париж является столицей Франции."
Даже после удаления пробелов и преобразования в нижний регистр эти две строки не идентичны. В результате функция неправильно вернет оценку точности 0.0, даже если оба предложения передают одинаковый смысл.
Прямолинейное сравнение не справляется с оценкой семантического сходства, успешно работая только если ответ агента точно соответствует ожидаемому выходу. Более эффективная оценка требует продвинутых техник обработки естественного языка (NLP) для различения смысла между предложениями. Для тщательной оценки AI агентов в реальных сценариях часто необходимы более сложные метрики. Эти метрики могут включать меры сходства строк, такие как расстояние Левенштейна и сходство Жаккара, анализ ключевых слов для присутствия или отсутствия конкретных ключевых слов, семантическое сходство с использованием косинусного сходства с моделями эмбеддингов, оценки LLM-as-a-Judge (обсуждаемые позже для оценки нюансированной корректности и полезности), и RAG-специфические метрики, такие как верность и релевантность.
Мониторинг латентности: Мониторинг латентности для действий агента имеет решающее значение в приложениях, где скорость ответа или действия AI агента является критическим фактором. Этот процесс измеряет продолжительность, необходимую агенту для обработки запросов и генерации выходных данных. Повышенная латентность может негативно повлиять на пользовательский опыт и общую эффективность агента, особенно в режиме реального времени или интерактивных средах. В практических применениях простой вывод данных латентности в консоль недостаточен. Рекомендуется логирование этой информации в постоянную систему хранения. Варианты включают структурированные лог-файлы (например, JSON), базы данных временных рядов (например, InfluxDB, Prometheus), хранилища данных (например, Snowflake, BigQuery, PostgreSQL) или платформы наблюдаемости (например, Datadog, Splunk, Grafana Cloud).
Отслеживание использования токенов для LLM взаимодействий: Для агентов, работающих на LLM, отслеживание использования токенов имеет решающее значение для управления затратами и оптимизации распределения ресурсов. Биллинг для LLM взаимодействий часто зависит от количества обработанных токенов (входных и выходных). Поэтому эффективное использование токенов напрямую снижает операционные расходы. Дополнительно, мониторинг количества токенов помогает выявить потенциальные области для улучшения в процессах prompt engineering или генерации ответов.
# Это концептуально, так как фактический подсчет токенов зависит от LLM API
class LLMInteractionMonitor:
def __init__(self):
self.total_input_tokens = 0
self.total_output_tokens = 0
def record_interaction(self, prompt: str, response: str):
# В реальном сценарии используйте счетчик токенов LLM API или токенизатор
input_tokens = len(prompt.split()) # Заглушка
output_tokens = len(response.split()) # Заглушка
self.total_input_tokens += input_tokens
self.total_output_tokens += output_tokens
print(f"Записано взаимодействие: Входные токены={input_tokens}, Выходные токены={output_tokens}")
def get_total_tokens(self):
return self.total_input_tokens, self.total_output_tokens
# Пример использования
monitor = LLMInteractionMonitor()
monitor.record_interaction("Какая столица Франции?", "Столица Франции - Париж.")
monitor.record_interaction("Расскажи шутку.", "Почему ученые не доверяют атомам? Потому что они все выдумывают!")
input_t, output_t = monitor.get_total_tokens()
print(f"Общие входные токены: {input_t}, Общие выходные токены: {output_t}")Этот раздел представляет концептуальный Python класс LLMInteractionMonitor, разработанный для отслеживания использования токенов во взаимодействиях с большими языковыми моделями. Класс включает счетчики как для входных, так и для выходных токенов. Его метод record_interaction имитирует подсчет токенов, разделяя строки промпта и ответа. В практической реализации использовались бы конкретные токенизаторы LLM API для точного подсчета токенов. По мере возникновения взаимодействий монитор накапливает общее количество входных и выходных токенов. Метод get_total_tokens обеспечивает доступ к этим накопленным итогам, необходимым для управления затратами и оптимизации использования LLM.
Пользовательская метрика для "полезности" с использованием LLM-as-a-Judge: Оценка субъективных качеств, таких как "полезность" AI агента, представляет вызовы, выходящие за рамки стандартных объективных метрик. Потенциальная система включает использование LLM в качестве оценщика. Этот подход LLM-as-a-Judge оценивает выходные данные другого AI агента на основе предопределенных критериев "полезности". Используя продвинутые лингвистические способности LLM, этот метод предлагает нюансированные, человекоподобные оценки субъективных качеств, превосходящие простое сопоставление ключевых слов или оценки на основе правил. Хотя эта техника находится в разработке, она показывает перспективы для автоматизации и масштабирования качественных оценок.
import google.generativeai as genai
import os
import json
import logging
from typing import Optional
# --- Конфигурация ---
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# Установите ваш API ключ как переменную окружения для запуска этого скрипта
# Например, в вашем терминале: export GOOGLE_API_KEY='your_key_here'
try:
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
except KeyError:
logging.error("Ошибка: переменная окружения GOOGLE_API_KEY не установлена.")
exit(1)
# --- Рубрика LLM-as-a-Judge для качества правовых опросов ---
LEGAL_SURVEY_RUBRIC = """
Вы эксперт по методологии правовых опросов и критический правовой рецензент. Ваша задача - оценить качество данного вопроса правового опроса.
Предоставьте оценку от 1 до 5 за общее качество, вместе с подробным обоснованием и конкретной обратной связью.
Сосредоточьтесь на следующих критериях:
1. **Ясность и точность (Оценка 1-5):**
* 1: Крайне расплывчато, очень двусмысленно или запутанно.
* 3: Умеренно ясно, но могло бы быть более точным.
* 5: Совершенно ясно, недвусмысленно и точно в правовой терминологии (если применимо) и намерении.
2. **Нейтральность и предвзятость (Оценка 1-5):**
* 1: Сильно наводящий или предвзятый, явно влияющий на респондента к конкретному ответу.
* 3: Слегка суггестивный или может быть интерпретирован как наводящий.
* 5: Полностью нейтральный, объективный и свободный от любого наводящего языка или нагруженных терминов.
3. **Релевантность и фокус (Оценка 1-5):**
* 1: Не относится к заявленной теме опроса или выходит за рамки.
* 3: Слабо связан, но мог бы быть более сфокусированным.
* 5: Напрямую относится к целям опроса и хорошо сфокусирован на одной концепции.
4. **Полнота (Оценка 1-5):**
* 1: Опускает критическую информацию, необходимую для точного ответа, или предоставляет недостаточный контекст.
* 3: В основном полный, но отсутствуют незначительные детали.
* 5: Предоставляет весь необходимый контекст и информацию для респондента, чтобы ответить полно.
5. **Соответствие аудитории (Оценка 1-5):**
* 1: Использует жаргон, недоступный целевой аудитории, или чрезмерно упрощен для экспертов.
* 3: В целом подходящий, но некоторые термины могут быть сложными или упрощенными.
* 5: Идеально адаптирован к предполагаемым правовым знаниям и опыту целевой аудитории опроса.
**Формат вывода:**
Ваш ответ ДОЛЖЕН быть JSON объектом со следующими ключами:
* `overall_score`: Целое число от 1 до 5 (среднее оценок критериев или ваше целостное суждение).
* `rationale`: Краткое резюме, почему была дана эта оценка, выделяющее основные сильные и слабые стороны.
* `detailed_feedback`: Список в виде пунктов, детализирующий обратную связь по каждому критерию (Ясность, Нейтральность, Релевантность, Полнота, Соответствие аудитории). Предложите конкретные улучшения.
* `concerns`: Список любых конкретных правовых, этических или методологических проблем.
* `recommended_action`: Краткая рекомендация (например, "Пересмотреть для нейтральности", "Одобрить как есть", "Уточнить область").
"""
class LLMJudgeForLegalSurvey:
"""Класс для оценки вопросов правовых опросов с использованием генеративной AI модели."""
def __init__(self, model_name: str = 'gemini-1.5-flash-latest', temperature: float = 0.2):
"""
Инициализирует LLM Judge.
Args:
model_name (str): Имя модели Gemini для использования.
'gemini-1.5-flash-latest' рекомендуется для скорости и стоимости.
'gemini-1.5-pro-latest' предлагает наивысшее качество.
temperature (float): Температура генерации. Ниже лучше для детерминированной оценки.
"""
self.model = genai.GenerativeModel(model_name)
self.temperature = temperature
def _generate_prompt(self, survey_question: str) -> str:
"""Конструирует полный промпт для LLM судьи."""
return f"{LEGAL_SURVEY_RUBRIC}\n\n---\n**ВОПРОС ПРАВОВОГО ОПРОСА ДЛЯ ОЦЕНКИ:**\n{survey_question}\n---"
def judge_survey_question(self, survey_question: str) -> Optional[dict]:
"""
Судит качество одного вопроса правового опроса с использованием LLM.
Args:
survey_question (str): Вопрос правового опроса для оценки.
Returns:
Optional[dict]: Словарь, содержащий суждение LLM, или None при ошибке.
"""
full_prompt = self._generate_prompt(survey_question)
try:
logging.info(f"Отправка запроса к '{self.model.model_name}' для суждения...")
response = self.model.generate_content(
full_prompt,
generation_config=genai.types.GenerationConfig(
temperature=self.temperature,
response_mime_type="application/json"
)
)
# Проверка модерации контента или других причин пустого ответа
if not response.parts:
safety_ratings = response.prompt_feedback.safety_ratings
logging.error(f"Ответ LLM был пустым или заблокирован. Рейтинги безопасности: {safety_ratings}")
return None
return json.loads(response.text)
except json.JSONDecodeError:
logging.error(f"Не удалось декодировать ответ LLM как JSON. Сырой ответ: {response.text}")
return None
except Exception as e:
logging.error(f"Произошла неожиданная ошибка во время суждения LLM: {e}")
return None
# --- Пример использования ---
if __name__ == "__main__":
judge = LLMJudgeForLegalSurvey()
# --- Хороший пример ---
good_legal_survey_question = """
В какой степени вы согласны или не согласны с тем, что текущие законы об интеллектуальной собственности в Швейцарии адекватно защищают появляющийся AI-генерированный контент, предполагая, что контент соответствует критериям оригинальности, установленным Федеральным Верховным Судом?
(Выберите один: Полностью не согласен, Не согласен, Нейтрально, Согласен, Полностью согласен)
"""
print("\n--- Оценка хорошего вопроса правового опроса ---")
judgment_good = judge.judge_survey_question(good_legal_survey_question)
if judgment_good:
print(json.dumps(judgment_good, indent=2, ensure_ascii=False))
# --- Предвзятый/плохой пример ---
biased_legal_survey_question = """
Разве вы не согласны, что чрезмерно ограничительные законы о конфиденциальности данных, такие как FADP, препятствуют необходимым технологическим инновациям и экономическому росту в Швейцарии?
(Выберите один: Да, Нет)
"""
print("\n--- Оценка предвзятого вопроса правового опроса ---")
judgment_biased = judge.judge_survey_question(biased_legal_survey_question)
if judgment_biased:
print(json.dumps(judgment_biased, indent=2, ensure_ascii=False))
# --- Двусмысленный/расплывчатый пример ---
vague_legal_survey_question = """
Каковы ваши мысли о правовых технологиях?
"""
print("\n--- Оценка расплывчатого вопроса правового опроса ---")
judgment_vague = judge.judge_survey_question(vague_legal_survey_question)
if judgment_vague:
print(json.dumps(judgment_vague, indent=2, ensure_ascii=False))Python код определяет класс LLMJudgeForLegalSurvey, предназначенный для оценки качества вопросов правовых опросов с использованием генеративной AI модели. Он использует библиотеку google.generativeai для взаимодействия с моделями Gemini.
Основная функциональность включает отправку вопроса опроса модели вместе с детальной рубрикой для оценки. Рубрика определяет пять критериев для судейства вопросов опроса: Ясность и точность, Нейтральность и предвзятость, Релевантность и фокус, Полнота и Соответствие аудитории. Для каждого критерия присваивается оценка от 1 до 5, и требуется детальное обоснование и обратная связь в выводе. Код конструирует промпт, который включает рубрику и вопрос опроса для оценки.
Метод judge_survey_question отправляет этот промпт сконфигурированной модели Gemini, запрашивая JSON ответ, отформатированный согласно определенной структуре. Ожидаемый выходной JSON включает общую оценку, резюме обоснования, детальную обратную связь по каждому критерию, список проблем и рекомендуемое действие. Класс обрабатывает потенциальные ошибки во время взаимодействия с AI моделью, такие как проблемы декодирования JSON или пустые ответы. Скрипт демонстрирует свою работу, оценивая примеры вопросов правовых опросов, иллюстрируя, как AI оценивает качество на основе предопределенных критериев.
Прежде чем мы завершим, давайте рассмотрим различные методы оценки, учитывая их сильные и слабые стороны.
| Метод оценки | Сильные стороны | Слабые стороны |
|---|---|---|
| Человеческая оценка | Улавливает тонкое поведение | Сложно масштабировать, дорого и затратно по времени, поскольку учитывает субъективные человеческие факторы |
| LLM-as-a-Judge | Последовательный, эффективный и масштабируемый | Промежуточные шаги могут быть упущены. Ограничен возможностями LLM |
| Автоматизированные метрики | Масштабируемые, эффективные и объективные | Потенциальное ограничение в улавливании полных возможностей |
Траектории агентов
Оценка траекторий агентов имеет решающее значение, поскольку традиционные тесты программного обеспечения недостаточны. Стандартный код дает предсказуемые результаты прохождения/провала, тогда как агенты работают вероятностно, требуя качественной оценки как итогового результата, так и траектории агента — последовательности шагов, предпринятых для достижения решения. Оценка мультиагентных систем является сложной задачей, поскольку они постоянно изменяются. Это требует разработки сложных метрик, которые выходят за рамки индивидуальной производительности для измерения эффективности коммуникации и командной работы. Более того, сами среды не являются статичными, что требует адаптации методов оценки, включая тестовые случаи, с течением времени.
Это включает изучение качества решений, процесса рассуждения и общего результата. Внедрение автоматизированных оценок ценно, особенно для разработки за пределами стадии прототипа. Анализ траектории и использования инструментов включает оценку шагов, которые агент использует для достижения цели, таких как выбор инструментов, стратегии и эффективность задач. Например, агент, отвечающий на запрос клиента о продукте, в идеале должен следовать траектории, включающей определение намерения, использование инструмента поиска в базе данных, обзор результатов и генерацию отчета. Фактические действия агента сравниваются с этой ожидаемой, или ground truth, траекторией для выявления ошибок и неэффективности.
Методы сравнения включают точное совпадение (требующее идеального соответствия идеальной последовательности), упорядоченное совпадение (правильные действия в порядке, допускающие дополнительные шаги), совпадение в любом порядке (правильные действия в любом порядке, допускающие дополнительные шаги), точность (измеряющую релевантность предсказанных действий), полноту (измеряющую сколько основных действий захвачено) и использование одного инструмента (проверяющее конкретное действие). Выбор метрики зависит от конкретных требований агента, при этом высокорисковые сценарии потенциально требуют точного совпадения, в то время как более гибкие ситуации могут использовать упорядоченное или неупорядоченное совпадение.
Оценка AI агентов включает два основных подхода: использование тестовых файлов и использование evalset файлов. Тестовые файлы в формате JSON представляют одиночные, простые взаимодействия агент-модель или сессии и идеальны для юнит-тестирования во время активной разработки, фокусируясь на быстром выполнении и простой сложности сессий. Каждый тестовый файл содержит одну сессию с множественными поворотами, где поворот — это взаимодействие пользователь-агент, включающее запрос пользователя, ожидаемую траекторию использования инструментов, промежуточные ответы агента и финальный ответ.
Например, тестовый файл может детализировать запрос пользователя "Выключить device_2 в спальне", указывая использование агентом инструмента set_device_info с параметрами, такими как location: Bedroom, device_id: device_2 и status: OFF, и ожидаемый финальный ответ "Я установил статус device_2 в выключено". Тестовые файлы могут быть организованы в папки и могут включать файл test_config.json для определения критериев оценки.
Evalset файлы используют набор данных, называемый "evalset", для оценки взаимодействий, содержащий множественные потенциально длительные сессии, подходящие для симуляции сложных, многооборотных разговоров и интеграционных тестов. Evalset файл состоит из множественных "evals", каждый представляющий отдельную сессию с одним или более "поворотами", которые включают пользовательские запросы, ожидаемое использование инструментов, промежуточные ответы и референсный финальный ответ.
Пример evalset может включать сессию, где пользователь сначала спрашивает "Что ты можешь делать?", а затем говорит "Брось 10-сторонний кубик дважды, а затем проверь, является ли 9 простым числом или нет", определяя ожидаемые вызовы инструмента roll_die и вызов инструмента check_prime, вместе с финальным ответом, резюмирующим броски кубика и проверку простого числа.
Мультиагенты: Оценка сложной AI системы с множественными агентами очень похожа на оценку командного проекта. Поскольку существует много шагов и передач, ее сложность является преимуществом, позволяя проверить качество работы на каждом этапе. Вы можете изучить, насколько хорошо каждый отдельный "агент" выполняет свою конкретную работу, но вы также должны оценить, как вся система работает в целом.
Для этого вы задаете ключевые вопросы о динамике команды, подкрепленные конкретными примерами:
Эффективно ли сотрудничают агенты? Например, после того как 'Агент бронирования рейсов' обеспечивает рейс, успешно ли он передает правильные даты и место назначения 'Агенту бронирования отелей'? Неудача в сотрудничестве может привести к бронированию отеля на неправильную неделю.
Создали ли они хороший план и придерживаются ли его? Представьте, что план состоит в том, чтобы сначала забронировать рейс, затем отель. Если 'Агент отелей' пытается забронировать комнату до подтверждения рейса, он отклонился от плана. Вы также проверяете, не застревает ли агент, например, бесконечно ища "идеальный" арендованный автомобиль и никогда не переходя к следующему шагу.
Выбирается ли правильный агент для правильной задачи? Если пользователь спрашивает о погоде для своей поездки, система должна использовать специализированный 'Агент погоды', который предоставляет живые данные. Если вместо этого она использует 'Агент общих знаний', который дает общий ответ типа "летом обычно тепло", она выбрала неправильный инструмент для работы.
Наконец, улучшает ли добавление большего количества агентов производительность? Если вы добавляете нового 'Агента бронирования ресторанов' в команду, делает ли это общее планирование поездки лучше и более эффективным? Или это создает конфликты и замедляет систему, указывая на проблему масштабируемости?
От агентов к продвинутым подрядчикам
Недавно была предложена (Agent Companion, gulli et al.) эволюция от простых AI агентов к продвинутым "подрядчикам", переход от вероятностных, часто ненадежных систем к более детерминированным и подотчетным системам, предназначенным для сложных, высокорисковых сред (см. рис. 2).
Сегодняшние обычные AI агенты работают на основе кратких, недостаточно специфицированных инструкций, что делает их подходящими для простых демонстраций, но хрупкими в производстве, где двусмысленность приводит к неудаче. Модель "подрядчика" решает это, устанавливая строгие, формализованные отношения между пользователем и AI, построенные на основе четко определенных и взаимно согласованных условий, во многом как соглашение о правовых услугах в человеческом мире. Эта трансформация поддерживается четырьмя ключевыми столпами, которые коллективно обеспечивают ясность, надежность и устойчивое выполнение задач, которые ранее были за пределами возможностей автономных систем.
Первым является столп формализованного контракта, детальной спецификации, которая служит единственным источником истины для задачи. Он выходит далеко за рамки простого промпта. Например, контракт для задачи финансового анализа не просто скажет "проанализировать продажи последнего квартала"; он потребует "20-страничный PDF отчет, анализирующий продажи на европейском рынке с Q1 2025, включая пять конкретных визуализаций данных, сравнительный анализ с Q1 2024 и оценку рисков на основе включенного набора данных о нарушениях цепочки поставок". Этот контракт явно определяет требуемые результаты, их точные спецификации, допустимые источники данных, область работы и даже ожидаемую вычислительную стоимость и время завершения, делая результат объективно проверяемым.
Вторым является столп динамического жизненного цикла переговоров и обратной связи. Контракт не является статичной командой, а началом диалога. Агент-подрядчик может проанализировать первоначальные условия и вести переговоры. Например, если контракт требует использования конкретного проприетарного источника данных, к которому агент не может получить доступ, он может вернуть обратную связь, заявив: "Указанная база данных XYZ недоступна. Пожалуйста, предоставьте учетные данные или одобрите использование альтернативной публичной базы данных, что может слегка изменить детализацию данных". Эта фаза переговоров, которая также позволяет агенту отмечать двусмысленности или потенциальные риски, разрешает недоразумения до начала выполнения, предотвращая дорогостоящие неудачи и обеспечивая идеальное соответствие итогового результата фактическому намерению пользователя.
Рис. 2: Пример выполнения контракта между агентами
Третьим столпом является качественно-ориентированное итеративное выполнение. В отличие от агентов, предназначенных для низколатентных ответов, подрядчик приоритизирует корректность и качество. Он работает по принципу самовалидации и коррекции. Для контракта генерации кода, например, агент не просто напишет код; он сгенерирует множественные алгоритмические подходы, скомпилирует и запустит их против набора юнит-тестов, определенных в контракте, оценит каждое решение по метрикам, таким как производительность, безопасность и читаемость, и представит только версию, которая проходит все критерии валидации. Этот внутренний цикл генерации, обзора и улучшения собственной работы до тех пор, пока спецификации контракта не будут выполнены, имеет решающее значение для построения доверия к его результатам.
Наконец, четвертым столпом является иерархическая декомпозиция через субконтракты. Для задач значительной сложности первичный агент-подрядчик может действовать как проект-менеджер, разбивая основную цель на меньшие, более управляемые подзадачи. Он достигает этого, генерируя новые, формальные "субконтракты". Например, мастер-контракт для "создания мобильного приложения электронной коммерции" может быть декомпозирован первичным агентом на субконтракты для "проектирования UI/UX", "разработки модуля аутентификации пользователей", "создания схемы базы данных продуктов" и "интеграции платежного шлюза". Каждый из этих субконтрактов является полным, независимым контрактом со своими собственными результатами и спецификациями, который может быть назначен другим специализированным агентам. Эта структурированная декомпозиция позволяет системе решать огромные, многогранные проекты высокоорганизованным и масштабируемым способом, отмечая переход AI от простого инструмента к истинно автономному и надежному движку решения проблем.
В конечном счете, эта система подрядчиков переосмысливает взаимодействие с AI, встраивая принципы формальной спецификации, переговоров и проверяемого выполнения непосредственно в основную логику агента. Этот методичный подход поднимает искусственный интеллект от многообещающего, но часто непредсказуемого помощника к надежной системе, способной автономно управлять сложными проектами с аудируемой точностью. Решая критические проблемы двусмысленности и надежности, эта модель прокладывает путь для развертывания AI в критически важных областях, где доверие и подотчетность являются первостепенными.
Google ADK
Перед завершением давайте рассмотрим конкретный пример фреймворка, который поддерживает оценку. Оценка агентов с помощью Google ADK (см. рис. 3) может проводиться тремя методами: веб-интерфейс (adk web) для интерактивной оценки и генерации наборов данных, программная интеграция с использованием pytest для включения в тестовые пайплайны и прямой интерфейс командной строки (adk eval) для автоматизированных оценок, подходящих для регулярной генерации и верификации сборок.
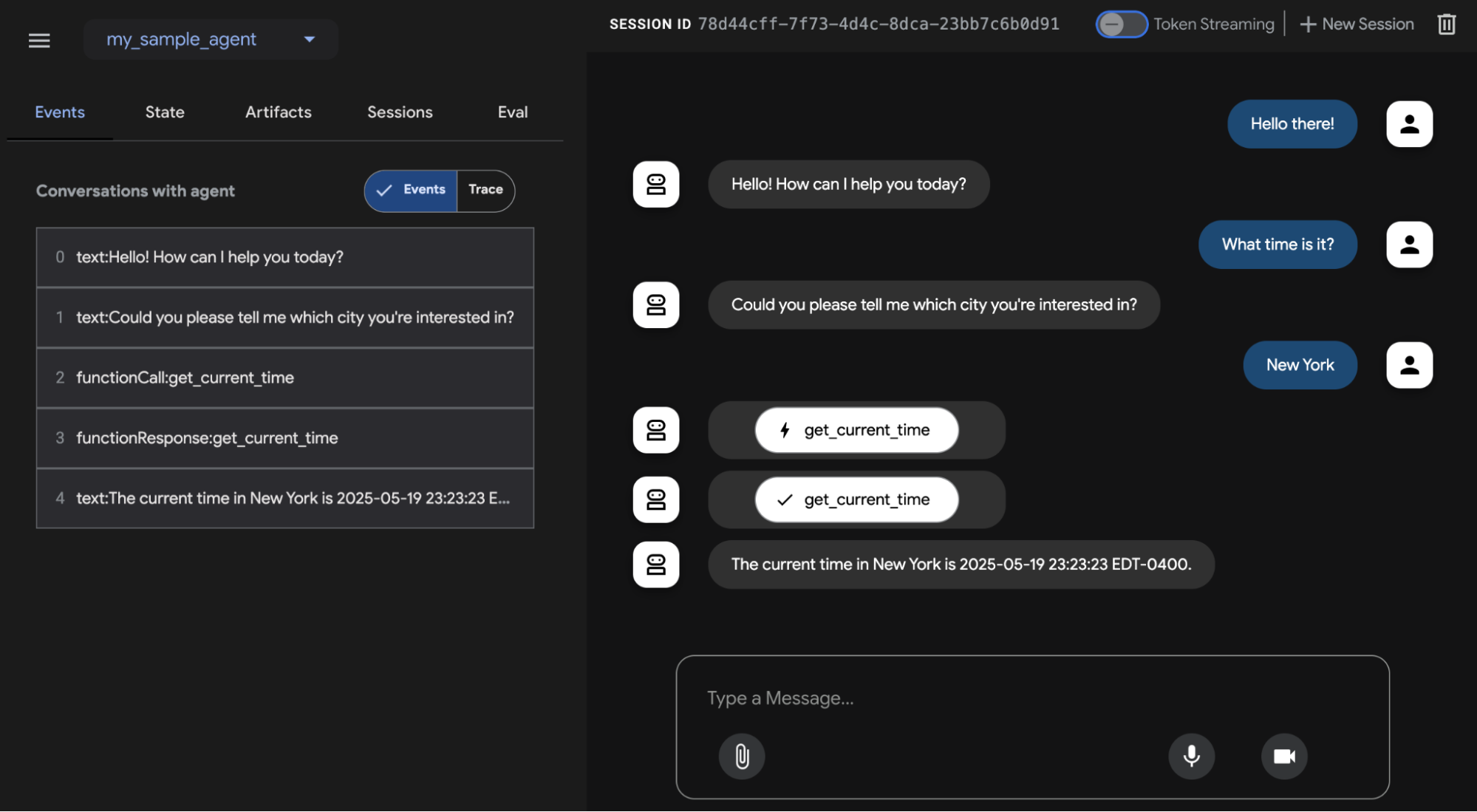
Рис. 3: Поддержка оценки для Google ADK
Веб-интерфейс позволяет создавать интерактивные сессии и сохранять их в существующие или новые eval наборы, отображая статус оценки. Интеграция с pytest позволяет запускать тестовые файлы как часть интеграционных тестов, вызывая AgentEvaluator.evaluate, указывая модуль агента и путь к тестовому файлу.
Интерфейс командной строки облегчает автоматизированную оценку, предоставляя путь к модулю агента и файл eval набора, с опциями для указания файла конфигурации или вывода детальных результатов. Конкретные evals в рамках большего eval набора могут быть выбраны для выполнения, перечисляя их после имени файла eval набора, разделенные запятыми.
В двух словах
Что: Агентные системы и LLM работают в сложных, динамичных средах, где их производительность может со временем ухудшаться. Их вероятностная и недетерминированная природа означает, что традиционное тестирование программного обеспечения недостаточно для обеспечения надежности. Оценка динамичных мультиагентных систем представляет значительный вызов, поскольку их постоянно изменяющаяся природа и природа их сред требуют разработки адаптивных методов тестирования и сложных метрик, которые могут измерять коллаборативный успех за пределами индивидуальной производительности. Проблемы, такие как дрейф данных, неожиданные взаимодействия, вызовы инструментов и отклонения от предполагаемых целей, могут возникнуть после развертывания. Поэтому необходима непрерывная оценка для измерения эффективности агента, производительности и соблюдения операционных требований и требований безопасности.
Почему: Стандартизированная система оценки и мониторинга предоставляет систематический способ оценки и обеспечения непрерывной производительности интеллектуальных агентов. Это включает определение четких метрик для точности, латентности и потребления ресурсов, таких как использование токенов для LLM. Это также включает продвинутые техники, такие как анализ агентных траекторий для понимания процесса рассуждения и использование LLM-as-a-Judge для нюансированных, качественных оценок. Устанавливая циклы обратной связи и системы отчетности, эта система позволяет непрерывное улучшение, A/B тестирование и обнаружение аномалий или дрейфа производительности, обеспечивая соответствие агента его целям.
Эмпирическое правило: Используйте этот шаблон при развертывании агентов в живых, производственных средах, где производительность в реальном времени и надежность критичны. Дополнительно, используйте его при необходимости систематического сравнения различных версий агента или его базовых моделей для стимулирования улучшений, и при работе в регулируемых или высокорисковых областях, требующих соответствия, безопасности и этических аудитов. Этот шаблон также подходит, когда производительность агента может ухудшаться со временем из-за изменений в данных или среде (дрейф), или при оценке сложного агентного поведения, включая последовательность действий (траекторию) и качество субъективных результатов, таких как полезность.
Визуальное резюме
Рис. 4: Шаблон проектирования оценки и мониторинга
Ключевые выводы
Оценка интеллектуальных агентов выходит за рамки традиционных тестов для непрерывного измерения их эффективности, производительности и соблюдения требований в реальных средах.
Практические применения оценки агентов включают отслеживание производительности в живых системах, A/B тестирование для улучшений, аудиты соответствия и обнаружение дрейфа или аномалий в поведении.
Базовая оценка агентов включает оценку точности ответов, в то время как реальные сценарии требуют более сложных метрик, таких как мониторинг латентности и отслеживание использования токенов для агентов, работающих на LLM.
Траектории агентов, последовательность шагов, которые агент предпринимает, имеют решающее значение для оценки, сравнивая фактические действия с идеальным, ground-truth путем для выявления ошибок и неэффективности.
ADK предоставляет структурированные методы оценки через индивидуальные тестовые файлы для юнит-тестирования и комплексные evalset файлы для интеграционного тестирования, оба определяющие ожидаемое поведение агента.
Оценки агентов могут выполняться через веб-интерфейс для интерактивного тестирования, программно с pytest для интеграции CI/CD или через интерфейс командной строки для автоматизированных рабочих процессов.
Чтобы сделать AI надежным для сложных, высокорисковых задач, мы должны перейти от простых промптов к формальным "контрактам", которые точно определяют проверяемые результаты и область действия. Это структурированное соглашение позволяет агентам вести переговоры, прояснять двусмысленности и итеративно валидировать свою собственную работу, трансформируя их из непредсказуемого инструмента в подотчетную и заслуживающую доверия систему.
Заключения
В заключение, эффективная оценка AI агентов требует выхода за рамки простых проверок точности к непрерывной, многогранной оценке их производительности в динамичных средах. Это включает практический мониторинг метрик, таких как латентность и потребление ресурсов, а также сложный анализ процесса принятия решений агента через его траекторию. Для нюансированных качеств, таких как полезность, инновационные методы, такие как LLM-as-a-Judge, становятся необходимыми, в то время как фреймворки, такие как Google ADK, предоставляют структурированные инструменты как для юнит-, так и для интеграционного тестирования. Вызов усиливается с мультиагентными системами, где фокус смещается на оценку коллаборативного успеха и эффективного сотрудничества.
Для обеспечения надежности в критических приложениях парадигма смещается от простых, управляемых промптами агентов к продвинутым "подрядчикам", связанным формальными соглашениями. Эти агенты-подрядчики работают на основе явных, проверяемых условий, позволяя им вести переговоры, декомпозировать задачи и самовалидировать свою работу для соответствия строгим стандартам качества. Этот структурированный подход трансформирует агентов из непредсказуемых инструментов в подотчетные системы, способные обрабатывать сложные, высокорисковые задачи. В конечном счете, эта эволюция имеет решающее значение для построения доверия, необходимого для развертывания сложного агентного AI в критически важных областях.
Ссылки
Соответствующие исследования включают:
- ADK Web: https://github.com/google/adk-web
- ADK Evaluate: https://google.github.io/adk-docs/evaluate/
- Survey on Evaluation of LLM-based Agents
- Agent-as-a-Judge: Evaluate Agents with Agents
- Agent Companion, gulli et al: https://www.kaggle.com/whitepaper-agent-companion
Навигация
Назад: Глава 18. Паттерны безопасности и защитные механизмы
Вперед: Глава 20. Приоритизация